






Jeremiah Smith and his Startup Tracker made a big splash on product review site, Product Hunt, recently. Startup Tracker 2.0 had just launched and received over 600 upvotes. Jeremiah joined Tradestreaming to talk about how investors are using the tools he developed to make better investment decisions in startups.
What is Startup Tracker and what was the inspiration behind starting it up? What was the itch you were trying to scratch?

As a founder, one of the crucial things you need to do is keep up with the general trends in the startup world and most importantly in the field your product is in. This means you spend a lot of time looking at, and reading about, what other startups are doing. Whether it’s for competitor analysis, growth strategy ideas or just curiosity, founders usually spend a lot of time keeping track of other people’s startups.
We used to do this by manually googling startups of interest, checking their various online profiles (about page, Crunchbase, Twitter etc. – if they existed) and aggregating the information in spreadsheets. Because the startup world is so dynamic, we had to spend significant amounts of time organizing our knowledge about startups – we even ended up getting an intern to help us, at which point we understood we had to handle this differently.
After failing to find a freely available dedicated solution to track startups, the product guys we are recognized the opportunity to be the first to market in something that was not only going to be very useful for us and fellow founders but also potentially for a wider segment of the startup community.
To test our hypothesis we participated in last year’s TC Disrupt EU hackathon where we won the Evernote prize and got further evidence of interest from actors in the startup community. Although it seems obvious retrospectively, pretty much everybody in the community is tracking startups one way or another. Whether it’s investors prospecting for deals, accelerators selecting candidates or corporate teams looking for partners, acquiring and organizing knowledge about startups is an essential part of people’s workflows. We thus proceeded to make a landing page and a MVP which we launched last December and given the very positive response once again, we proceeded to raise a pre-seed round to launch the proper product.
How are investors using it and how have you improved it since first launching?
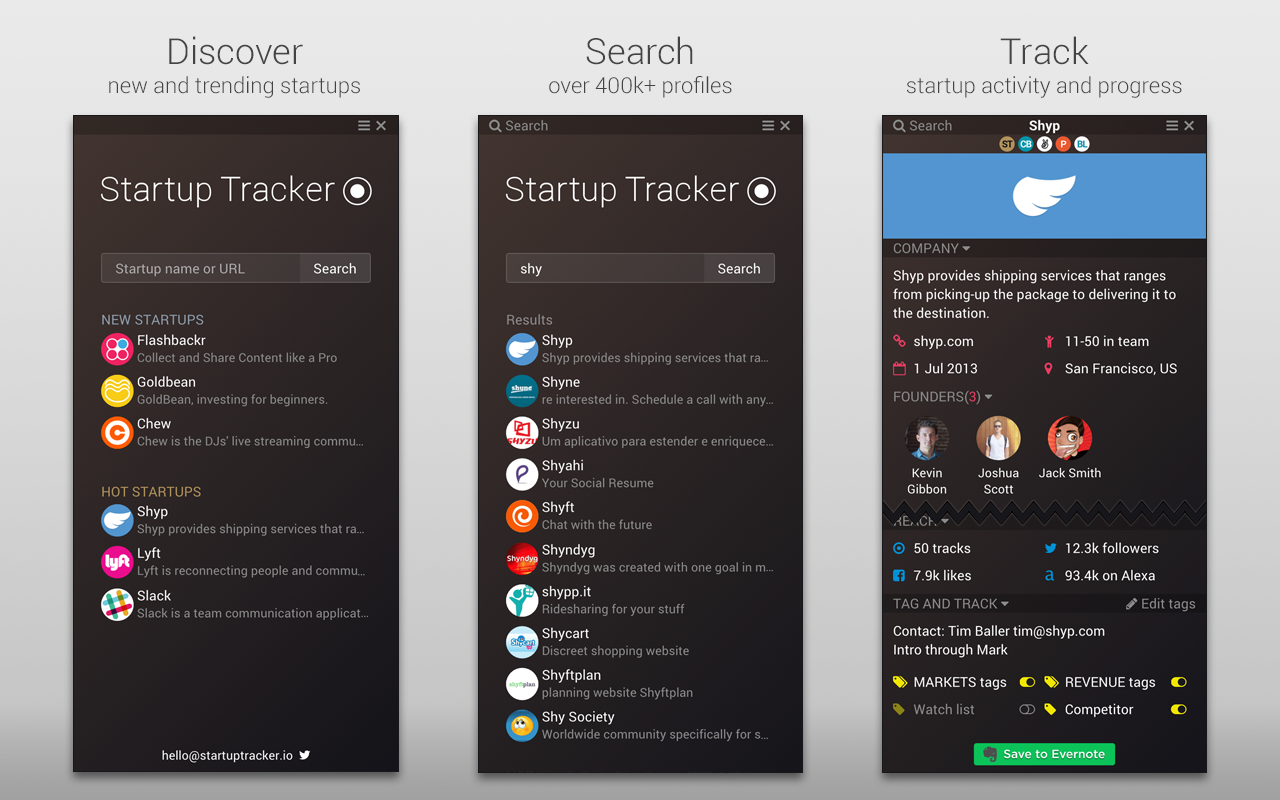
Investors, as pretty much everybody else, use Startup Tracker to get a 1-pager about startups they hear or read about and filter out startups that are relevant to them. Startup profiles of interests can be annotated and saved (to Evernote for now).
The first Startup Tracker we launched was very much an MVP. For Startup Tracker 2.0 we had to re-implement much of the back and front end to be able to offer it’s defining features:
- A customizable UI to display only the information a user needs
- An information aggregation platform to connect an arbitrary number of data providers to show the must up-to-date information for each startup profile field
- Live-search over all startups profiles; there are currently over 400k profiles across providers
- A crowdsourcing mechanism where users can request specific missing profile fields or entire profile updates from the startups they are interested in
How as the explosion of content and data on startups made it easier/harder to track them? Can you mention your crowdsourcing mechanism — is this a trend to include the crowd in building out the database? How do you ensure data integrity?
I would say the explosion is in the number of startups and their increasingly important role in our societies and economies and not in the actual data about them. Information about startups, specifically early-stage startups, is very much scattered, outdated or altogether inexistant hence the need for services like Startup Tracker.
It’s a hard problem because there is a wide range of potential data one can collect for a given startup and different types of information are more or less difficult to source. For instance, the investing side of the startup community likes to know about startups’ financial details like revenue which startups are not keen on sharing. Conversely, established companies looking for partners in a given niche are more interested in qualitative information such as the market a company is in, what the company does and who the founders are. These are theoretically easier to source as they are part of startups’ public identity but are often times not directly available in practice.
Using crowdsourcing is thus difficult to avoid given the amount and dispersion of information about startups, the question thus becomes: what information do we want to know, and who do we ask it from?
The most well-known startup information database today is CrunchBase. They use a crowdsourcing mechanism where anyone ‘can edit almost everything’ about any startup. This is great because it’s an easy way to source a lot of information. Throughout the years (it was founded in 2007 as a non-profit wiki) they have accumulated around 300k profiles. They also contribute information themselves and have editors which can amend user input (they claim to have had about 80k people contribute to their database in 2014, which also includes people, investments, events and schools). The downside is that data integrity is sometimes at risk. For instance, it has been the case that the website shown on Google’s company profile points to an unrelated promotional site, and auto-contributed information can be incomplete (Here is a good example with Startup Tracker).
We like to think that the approach Startup Tracker takes complements this type of crowdsourcing. We aggregate the existing knowledge over public providers: mainly CrunchBase, AngelList and Product Hunt, and enable users to ask a startup to fill in any missing information on it’s profile by clicking a button. We thus use a 2 legged crowdsourcing mechanism where users tell us the information they are interested in and we try to fetch it for them from the information holders directly. Startup Tracker thus restricts who can contribute to a given profile in exchange for guarantees about the data’s origin (a person who submits information for a startup must tweet us a verification code from the company’s official Twitter handle for us to publish the profile).
We are also developing partnerships to help centralize information from independent sites where one can ’submit their startup’. This way people keep the advantage of submitting their information to a local community while still making their startups easy to search globally. The bottom line is that we believe the best people to ask for data about a startup is the startup itself.
What is going to be the eventual revenue model?
Startup Tracker has two main aspects: gathering startup information and providing tools to work with startup information i.e. annotating, tracking, exporting, reporting etc. Up until now we’ve focused on gathering startup information as it is the prerequisite for data tools to be useful. We have chosen a Freemium revenue model where we will provide some tools for free and others for a monthly subscription fee, keeping a free high quality service for regular users and creating a paid tier for business users. We haven’t decided which of the tools eventually offered by Startup Tracker will be priced, but we have decided access to startup information will remain free.
Can you talk about how to think about distributing tools like ST 2.0? How are you growing your base? What can other apps learn from you?
Natural places to initially distribute startup-related products are Beta List and Product Hunt as they have a startup centric audience. These outlets are easy to reach once you have a solid MVP and are usually enough to reach your first 1000 users who can then help iterate over your MVP. A lot of people also submit their startups to various less known startup directories which in our experience does bring a small but continuous flow of users to your site (there are even businesses built around this including StartupLister and PromoteHour).
Startup Tracker’s current growth engine is based on Twitter. For instance, when we crowdsource a new startup profile it gets tweeted out. Often times the founders, or the startup in question, retweets the news, so that Startup Tracker gets promoted in their social network which probably contain people interested in startups hence potentially in Startup Tracker as well. Much of the process is automated so it scales well.
I don’t think there is a magic recipe in terms of growth, the only reliable pattern we’ve experience is to use communication channels where your target audience is, for the startup crowd Twitter is a good candidate. If you are targeting freelancers, content marketing via blog posts might be a better strategy etc.